SIMULATION DISTILLATION
Pretraining World Models in Simulation for Rapid Real-World Adaptation
1 UT Austin 2 UW 3 FieldAI * Equal Contribution
Rapid Real-World Adaptation
Simulation Distillation (SimDist) rapidly overcomes the sim-to-real dynamics gap through adaptation in the real world, resulting in substantial gains in task execution on both precise manipulation and quadrupedal locomotion tasks.
Table Leg
Slippery Slope
Foam
Why World Models?
End-to-end RL finetuning in the real world often forgets useful priors from simulation. SimDist keeps global task structure fixed and updates only what changes most across domains: dynamics.
End-to-end RL Finetuning is Hard
Sim-to-real policies fail under dynamics mismatch. Standard RL finetuning entangles representation, dynamics, and returns, forcing relearning of the entire task structure in the new domain.
World Models Factorize Problem Structure
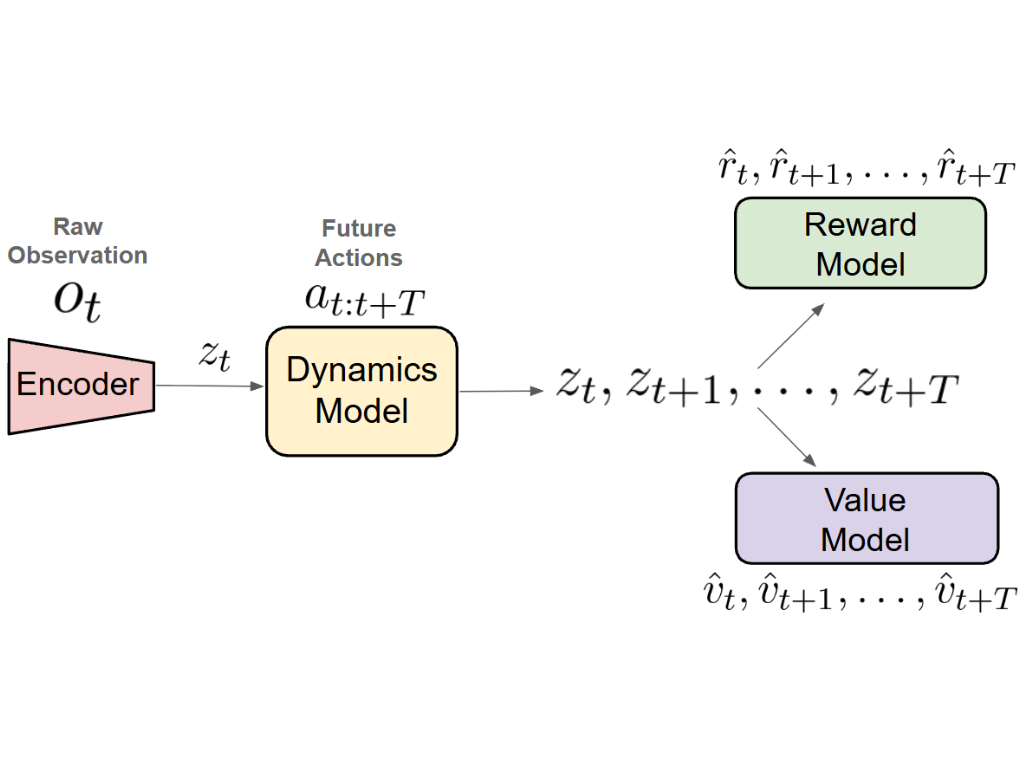
World models decompose task structure in a modular format we can exploit for efficient real-world adaptation.
Leveraging Simulation for Transferable Priors
Domain randomization and privileged state supervision yield robust representation and reward/value models in simulation, allowing real-world finetuning to focus solely on dynamics adaptation.
Introducing Simulation Distillation
Simulation Distillation (SimDist) is a scalable framework that distills structural priors from a simulator into a latent world model and enables rapid real-world adaptation via online planning and supervised dynamics finetuning.
Hover over a box to view its detail below.

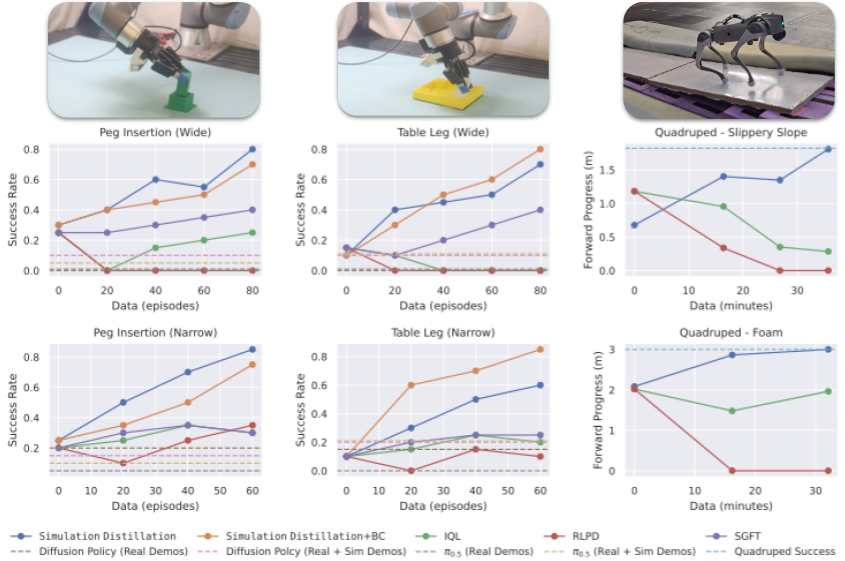
Real-World Results
Success rate for two manipulation tasks, computed over 20 trials, and average forward progress for two quadruped locomotion tasks, averaged across all 15 trials (3 speeds, 5 trials each), as a function of real-world finetuning data. For manipulation, we consider two difficulties: initial conditions drawn from a Narrow or Wide grid.
SimDist exhibits rapid and consistent improvement with limited data by finetuning only the latent dynamics model while planning with frozen reward and value models. In contrast, direct policy finetuning with the baselines shows limited or no improvement under the same data budgets.
Hover a plot to preview its video. Click to expand.
Interactive charts load here from assets/data/results.json.
Successful Return Model Transfer
The planner used by SimDist can only improve behavior if it can reliably distinguish trajectories with high and low returns. This requires both accurate dynamics prediction and successful transfer of reward and value models. We examine value transfer below, which plots predicted values over time for successful and failed trajectories.
For the successful rollout, predicted value increases consistently over time, while remaining lower for the failed trajectory. Thus the transfered encoder and value function can reliably discriminate between successful and failed trajectories.
Improving Dynamics Prediction with Finetuning
Next, we examine the effect finetuning has on dynamics prediction accuracy. Adapting the dynamics model is essential for effective planning, as both the reward and value estimates are computed over predicted trajectories.
Finetuning drastically lowers dynamics prediction loss for a held out quadruped slippery slope trajectory.
During this trajectory, the front-left foot slips.
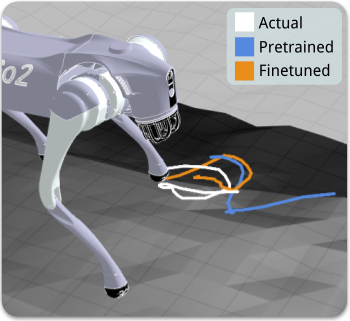
At this same instant, the finetuned model correctly anticipates the future slippage, while the pretrained model fails to do so.
Planning Under Adapted Dynamics
Because we finetune only the dynamics, adaptation is fast: improved predictions immediately reshape planning behavior, driving the performance gains seen in our results.